Yenny Rahmawati, 07 Feb 2026
Memahami Unsupervised Learning

Pengertian Unsupervised Learning
Unsupervised learning adalah salah satu jenis pembelajaran mesin (machine learning) yang mempelajari data tanpa menggunakan label atau pengawasan dari manusia. Pada metode ini, sistem tidak diberi tahu mana data yang benar atau salah, melainkan dibiarkan menganalisis data secara mandiri.
Tujuan utama dari unsupervised learning adalah menemukan pola tersembunyi, struktur, atau pengelompokan (cluster) dalam data. Metode ini sering digunakan untuk memahami karakteristik data, mengelompokkan data yang memiliki kemiripan, serta melakukan eksplorasi data sebelum tahap analisis atau pemodelan lebih lanjut.
Key Karakteristik Unsupervised Learning
1. Tanpa Data Berlabel (No Labeled Data)
Unsupervised learning tidak menggunakan data berlabel. Berbeda dengan supervised learning, model belajar langsung dari data mentah tanpa adanya target atau jawaban yang telah ditentukan sebelumnya.
2. Bersifat Eksploratif (Exploratory Nature)
Metode ini digunakan untuk eksplorasi data, dengan tujuan menemukan pola, hubungan, atau struktur tersembunyi yang sebelumnya tidak diketahui.
3. Beragam Aplikasi (Variety of Applications)
Unsupervised learning banyak diterapkan dalam berbagai bidang, seperti analisis data eksploratif, segmentasi pelanggan, sistem rekomendasi, deteksi anomali, dan pengelompokan data berdasarkan kemiripan.
Algoritma Unsupervised Learning
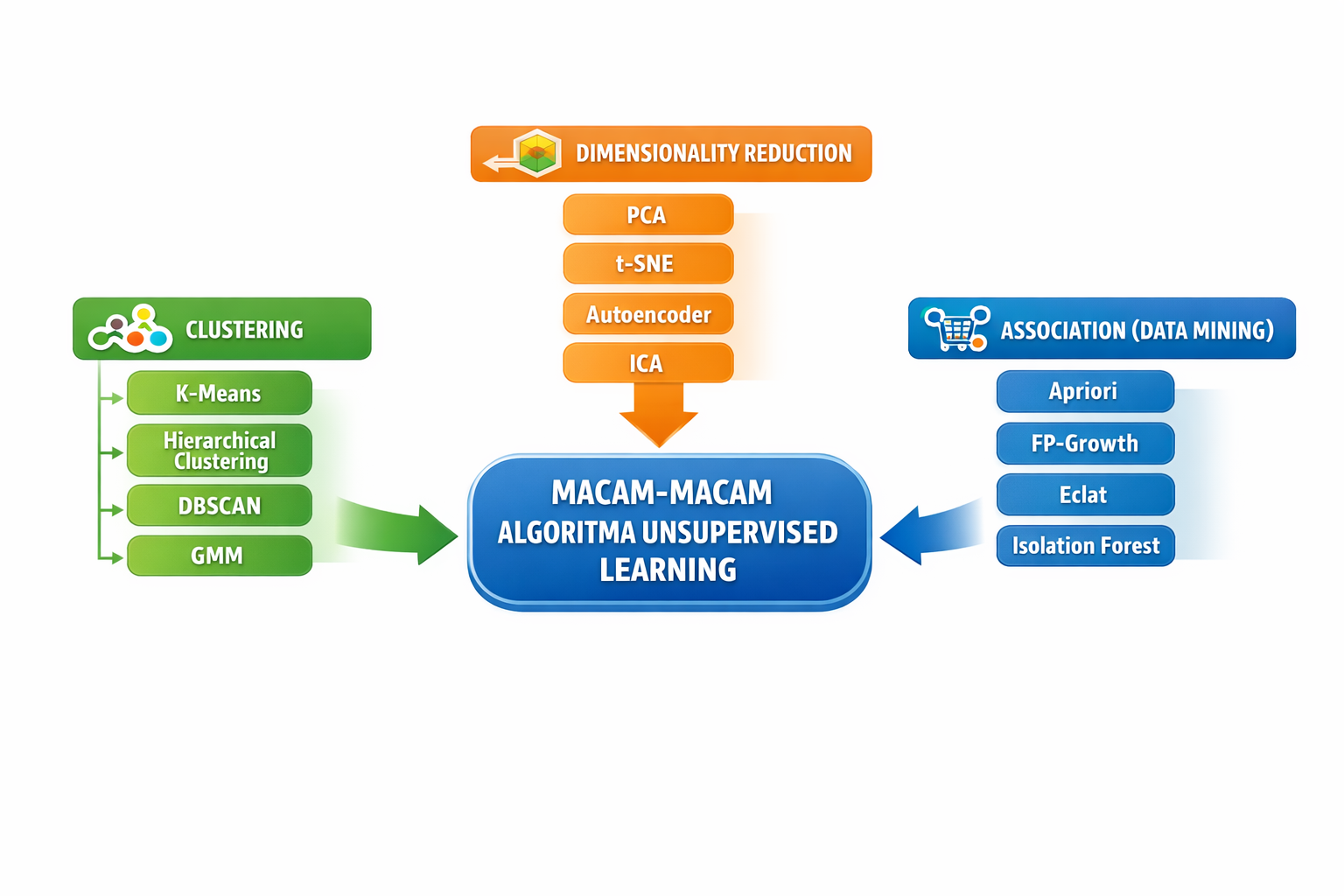
Algoritma unsupervised learning dapat dikelompokkan ke dalam beberapa kategori utama, yaitu clustering, dimensionality reduction, dan data mining
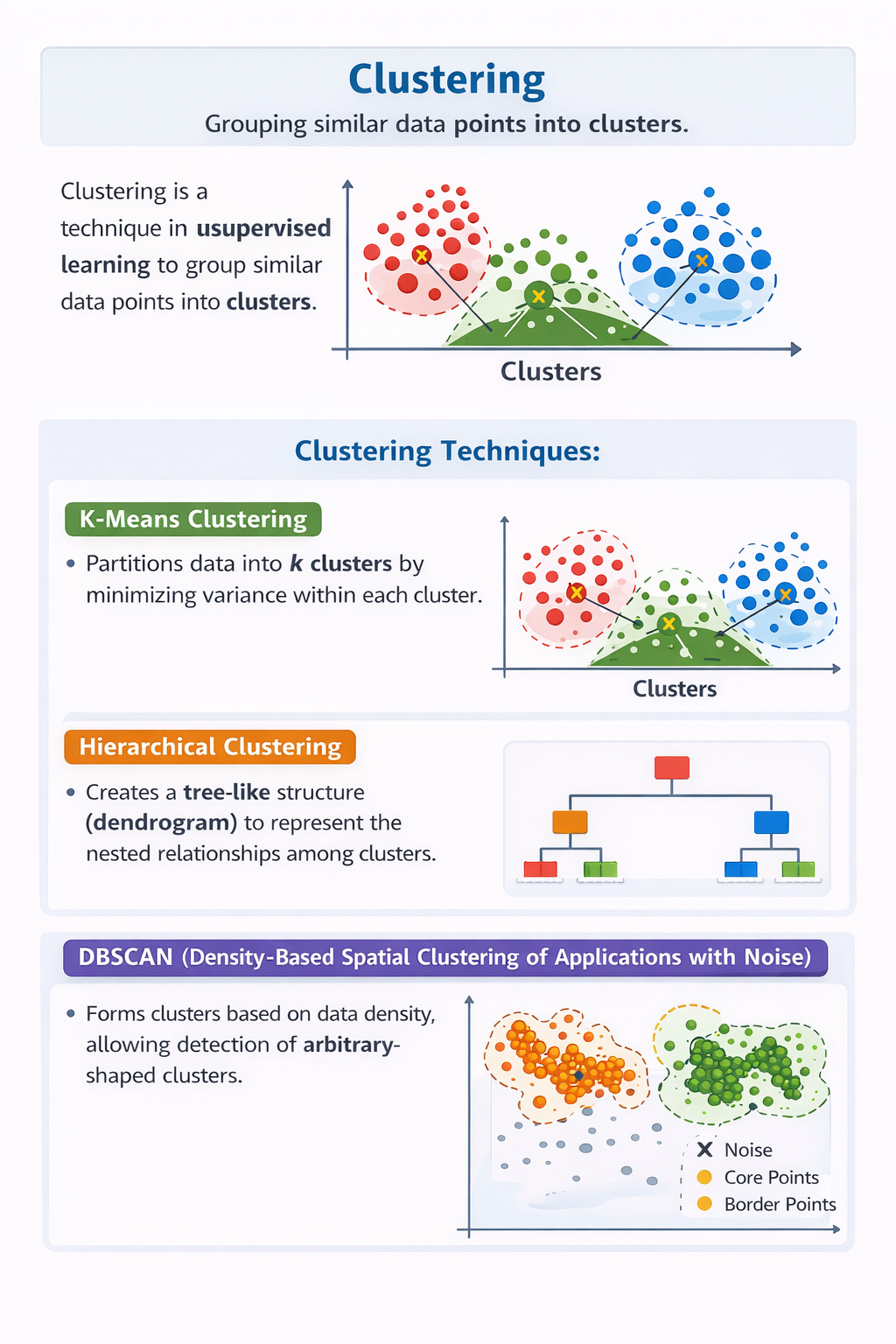
Clustering
Clustering adalah salah satu teknik dalam unsupervised learning yang bertujuan untuk mengelompokkan data yang memiliki kemiripan karakteristik ke dalam satu kelompok (cluster). Dalam clustering, data yang berada dalam satu cluster memiliki tingkat kemiripan yang tinggi, sedangkan data pada cluster yang berbeda memiliki perbedaan yang signifikan. Teknik ini banyak digunakan untuk menemukan pola atau struktur tersembunyi dalam data tanpa menggunakan label.
1. K-Means
K-Means Clustering adalah metode clustering yang membagi data ke dalam sejumlah k cluster dengan cara meminimalkan variansi di dalam setiap cluster. Algoritma ini bekerja dengan menentukan pusat cluster (centroid) dan mengelompokkan data berdasarkan jarak terdekat ke centroid tersebut. K-Means dikenal karena prosesnya yang sederhana dan efisien, namun membutuhkan penentuan jumlah cluster di awal. K-Means banyak digunakan dalam segmentasi pelanggan untuk mengelompokkan konsumen berdasarkan perilaku atau preferensi.
2. Hierarchical Clustering
Hierarchical Clustering membentuk struktur cluster secara bertingkat dan menghasilkan representasi berbentuk pohon atau dendrogram. Metode ini menunjukkan hubungan bertingkat antar cluster, mulai dari data yang paling mirip hingga yang paling berbeda. Keunggulan utama hierarchical clustering adalah tidak memerlukan jumlah cluster di awal, sehingga cocok untuk analisis eksploratif. Algoritma ini sering diterapkan dalam analisis genetik dan pengelompokan data akademik.
3. DBSCAN
DBSCAN merupakan teknik clustering berbasis kepadatan data, di mana cluster dibentuk berdasarkan daerah dengan kepadatan tinggi. Metode ini mampu mendeteksi cluster dengan bentuk yang tidak beraturan serta secara otomatis mengidentifikasi data noise atau outlier. DBSCAN sangat efektif digunakan pada data spasial dan data yang mengandung anomali.
4. Gaussian Mixture Model (GMM)
GMM bertujuan melakukan clustering dengan pendekatan probabilistik, di mana setiap data memiliki peluang untuk masuk ke suatu cluster. Ciri khasnya adalah fleksibilitas dalam menangani bentuk cluster yang kompleks. Algoritma ini sering digunakan dalam analisis perilaku pengguna.
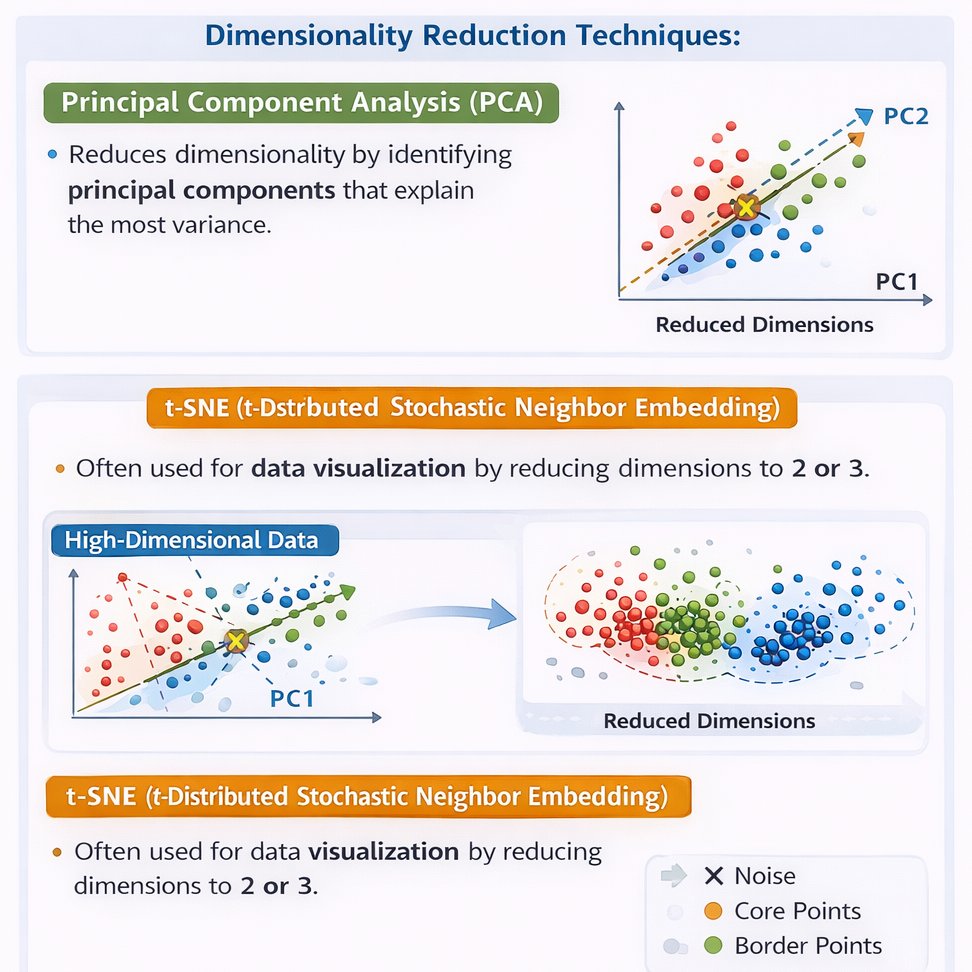
Dimensionality Reduction
Dimensionality reduction adalah teknik dalam unsupervised learning yang bertujuan untuk mengurangi jumlah fitur atau dimensi data dengan tetap mempertahankan informasi yang penting dan bermakna. Teknik ini sangat berguna ketika data memiliki banyak fitur, sehingga dapat menyulitkan proses analisis dan pemodelan.
Dengan mengurangi dimensi data, dimensionality reduction mampu menurunkan kompleksitas komputasi, mempercepat waktu pelatihan model, serta membantu visualisasi data agar pola dan struktur data lebih mudah dipahami oleh manusia.
Manfaat Dimensionality Reduction
- Mengurangi beban komputasi dan penggunaan memori
- Mempercepat proses pelatihan model machine learning
- Mengurangi risiko overfitting
- Memudahkan visualisasi dan eksplorasi data berdimensi tinggi
Teknik–Teknik Dimensionality Reduction
1. Principal Component Analysis (PCA)
Principal Component Analysis (PCA) merupakan teknik dimensionality reduction yang bekerja dengan mengidentifikasi komponen utama (principal components) yang mampu menjelaskan variansi terbesar dalam data. PCA mentransformasikan data ke ruang baru dengan dimensi yang lebih rendah, namun tetap mempertahankan sebagian besar informasi penting. Metode ini banyak digunakan pada tahap preprocessing dan visualisasi data.
2. t-Distributed Stochastic Neighbor Embedding (t-SNE)
t-SNE adalah teknik dimensionality reduction yang umumnya digunakan untuk visualisasi data berdimensi tinggi ke dalam dua atau tiga dimensi. Metode ini sangat efektif dalam mempertahankan hubungan lokal antar data, sehingga sering digunakan untuk menganalisis data kompleks dan melihat pola atau kelompok tersembunyi dalam dataset.
3. Autoencoder
Autoencoder bertujuan melakukan reduksi fitur menggunakan jaringan saraf tiruan. Ciri khasnya adalah kemampuannya menangani hubungan non-linear serta termasuk dalam pendekatan deep learning. Autoencoder banyak digunakan untuk kompresi data dan feature extraction.
4. Independent Component Analysis (ICA)
ICA bertujuan memisahkan sinyal-sinyal independen dari data campuran. Ciri khasnya adalah fokus pada independensi antar komponen. Algoritma ini sering diterapkan dalam pengolahan sinyal, seperti pemisahan suara atau sinyal EEG.
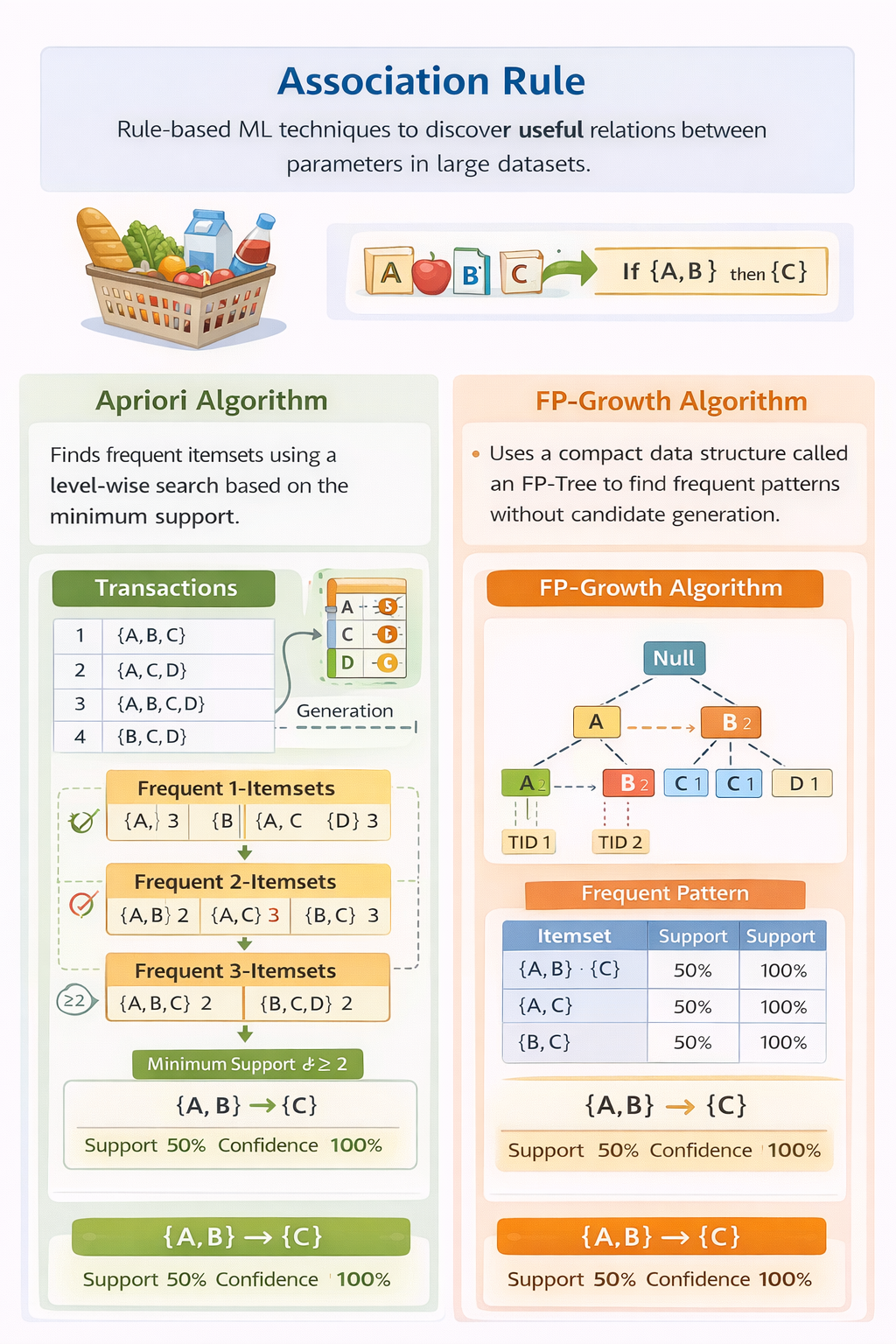
Association Rule
Association Rule adalah teknik machine learning berbasis aturan (rule-based) yang digunakan untuk menemukan hubungan atau keterkaitan yang bermakna antar parameter atau item dalam suatu dataset berukuran besar. Teknik ini bekerja dengan mengekstraksi pola-pola berupa aturan (if–then rules) yang menunjukkan bagaimana suatu item atau kejadian berkaitan dengan item lainnya.
Association Rule paling umum digunakan dalam market basket analysis, yaitu analisis data transaksi untuk memahami hubungan antar produk yang sering dibeli secara bersamaan oleh pelanggan. Hasil analisis ini dapat dimanfaatkan untuk strategi penataan produk, promosi, rekomendasi, dan pengambilan keputusan bisnis.
Konsep Dasar Association Rule
Association Rule biasanya dinyatakan dalam bentuk:
‘Jika A terjadi, maka B cenderung terjadi’
Untuk menilai kekuatan suatu aturan, digunakan beberapa metrik utama:
- Support: seberapa sering item muncul dalam dataset
- Confidence: tingkat kepercayaan bahwa B terjadi jika A terjadi
- Lift: tingkat kekuatan hubungan antara A dan B dibandingkan kejadian acak
####Teknik–Teknik Association Rule
1. Apriori
Apriori adalah algoritma Association Rule yang bekerja dengan cara mencari itemset yang sering muncul (frequent itemsets) berdasarkan nilai support minimum. Algoritma ini menggunakan prinsip bahwa jika suatu itemset tidak sering muncul, maka superset-nya juga tidak akan sering muncul. Apriori banyak digunakan dalam market basket analysis untuk menemukan pola pembelian pelanggan, meskipun memiliki kelemahan pada proses komputasi yang cukup berat untuk dataset besar.
2. FP-Growth
FP-Growth (Frequent Pattern Growth) merupakan pengembangan dari Apriori yang bertujuan untuk meningkatkan efisiensi pencarian pola. Algoritma ini menggunakan struktur data FP-Tree untuk menyimpan informasi transaksi sehingga tidak perlu melakukan pembangkitan kandidat itemset secara eksplisit. FP-Growth jauh lebih cepat dan efisien dibandingkan Apriori, terutama pada dataset berskala besar dan kompleks.
3. Eclat
Eclat bertujuan menemukan aturan asosiasi menggunakan pendekatan data vertikal. Ciri khasnya adalah kecepatan pemrosesan pada dataset berukuran besar. Algoritma ini sering diterapkan dalam analisis pola pembelian.
4. Isolation Forest atau Anomaly Detection
Isolation Forest bertujuan mendeteksi anomali dengan mengisolasi data yang jarang muncul. Ciri khasnya adalah efektivitasnya pada data berskala besar. Algoritma ini banyak digunakan dalam fraud detection dan keamanan data.