Yenny Rahmawati, 24 Jan 2026
Memahami Supervised Learning

Pengertian Supervised Learning
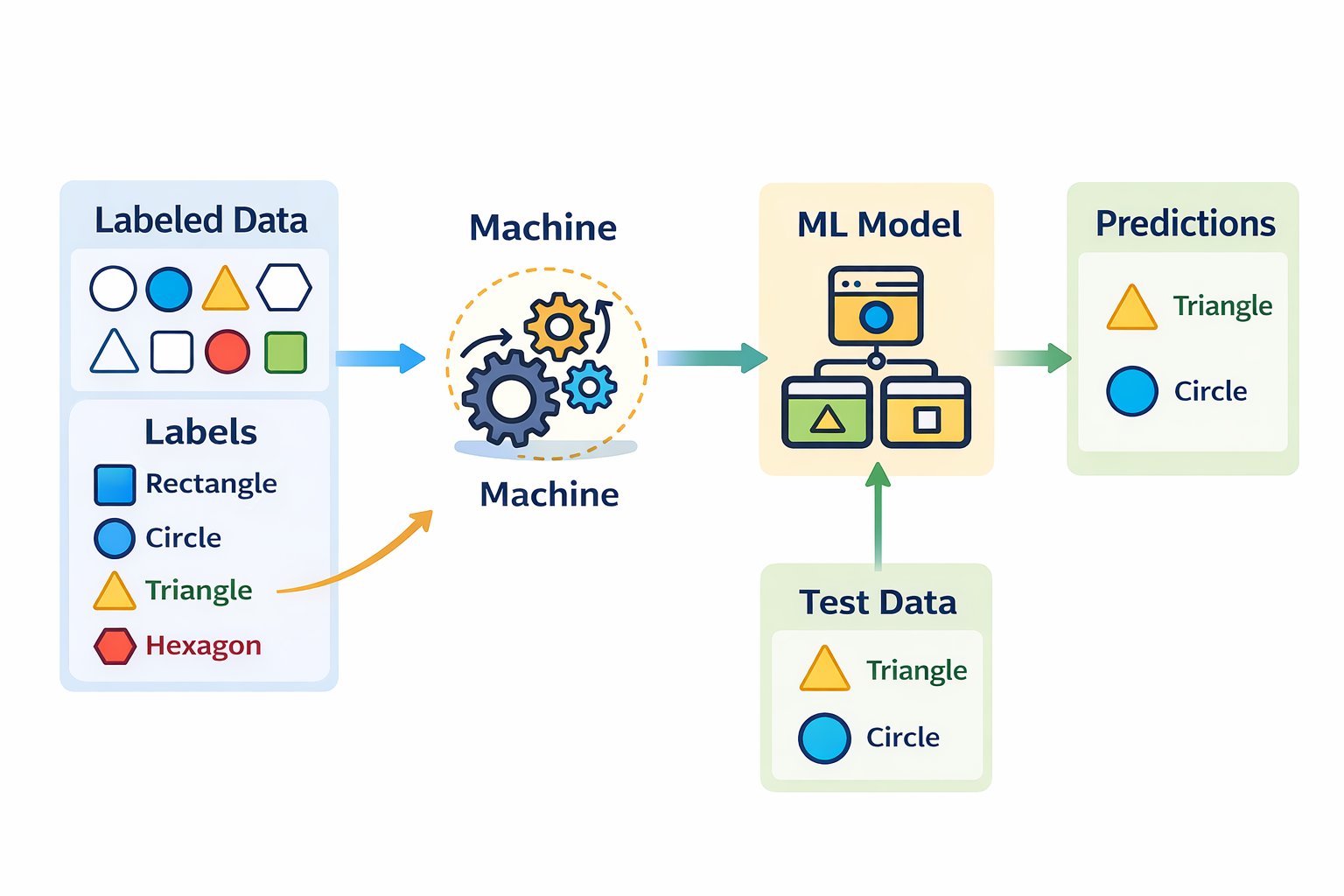
Supervised Learning adalah salah satu metode dalam machine learning di mana sistem belajar menggunakan data berlabel. Data berlabel berarti setiap data input sudah memiliki jawaban yang benar atau kelas target yang telah diketahui sebelumnya.
Pada supervised learning, proses pelatihan model dilakukan dengan memasukkan dua komponen utama, yaitu:
- Input (features): ciri atau atribut dari data
- Output (labels): nilai target atau kelas yang diharapkan Model akan mempelajari hubungan antara fitur dan label tersebut, sehingga mampu memahami pola yang ada di dalam data.
Tujuan Supervised Learning
Tujuan utama dari supervised learning adalah memprediksi data baru berdasarkan pola yang dipelajari dari contoh-contoh sebelumnya. Setelah proses pelatihan selesai, model diharapkan dapat memberikan prediksi yang akurat meskipun menghadapi data yang belum pernah dilihat sebelumnya.
Contoh Penerapan
- Memprediksi harga rumah berdasarkan luas dan lokasi
- Klasifikasi email menjadi spam atau non-spam
- Deteksi kondisi mengantuk atau normal berdasarkan fitur wajah
Dengan adanya data berlabel sebagai acuan, supervised learning menjadi metode yang sangat efektif untuk tugas klasifikasi dan prediksi dalam berbagai bidang seperti kesehatan, industri, pendidikan, dan kecerdasan buatan.
Mengapa Disebut Supervised Learning?
Istilah supervised learning berasal dari kata supervised yang berarti dibimbing atau diawasi. Metode ini disebut supervised karena proses pembelajarannya berlangsung di bawah pengawasan “guru” atau “pengawas”.
Analogi Pembelajaran
Supervised learning dapat dianalogikan seperti seseorang yang belajar hal baru di bawah bimbingan seorang guru. Guru tersebut:
- Memberikan contoh yang benar
- Menunjukkan mana jawaban yang tepat dan mana yang salah
- Membantu memperbaiki kesalahan selama proses belajar
Dengan cara ini, siswa dapat memahami pola dan aturan dengan lebih cepat dan akurat.
Peran Supervisor dalam Supervised Learning
Dalam supervised learning, supervisor atau guru berperan sebagai pakar (expert) yang memberikan label pada data. Label inilah yang menjadi acuan bagi model untuk belajar. Setiap data input sudah dilengkapi dengan jawaban yang benar, sehingga model dapat:
- Membandingkan hasil prediksi dengan label sebenarnya
- Mengoreksi kesalahan
- Meningkatkan akurasi secara bertahap
Inti dari Supervised Learning
Karena adanya data berlabel yang diberikan oleh “guru”, proses pembelajaran tidak berlangsung secara bebas, melainkan terarah dan terkontrol. Inilah alasan utama mengapa metode ini disebut supervised learning, yaitu pembelajaran mesin yang terjadi dengan pengawasan langsung melalui data yang telah diberi label.
Tipe Supervised Learning
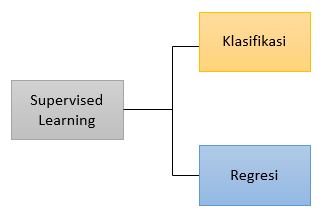
Klasifikasi
Klasifikasi adalah salah satu jenis metode dalam machine learning yang bertujuan untuk mengelompokkan atau memetakan data keluaran (output) ke dalam kategori tertentu. Pada model klasifikasi, sistem belajar dari data berlabel untuk menentukan kelas yang paling sesuai bagi suatu data input.
Jenis-Jenis Klasifikasi
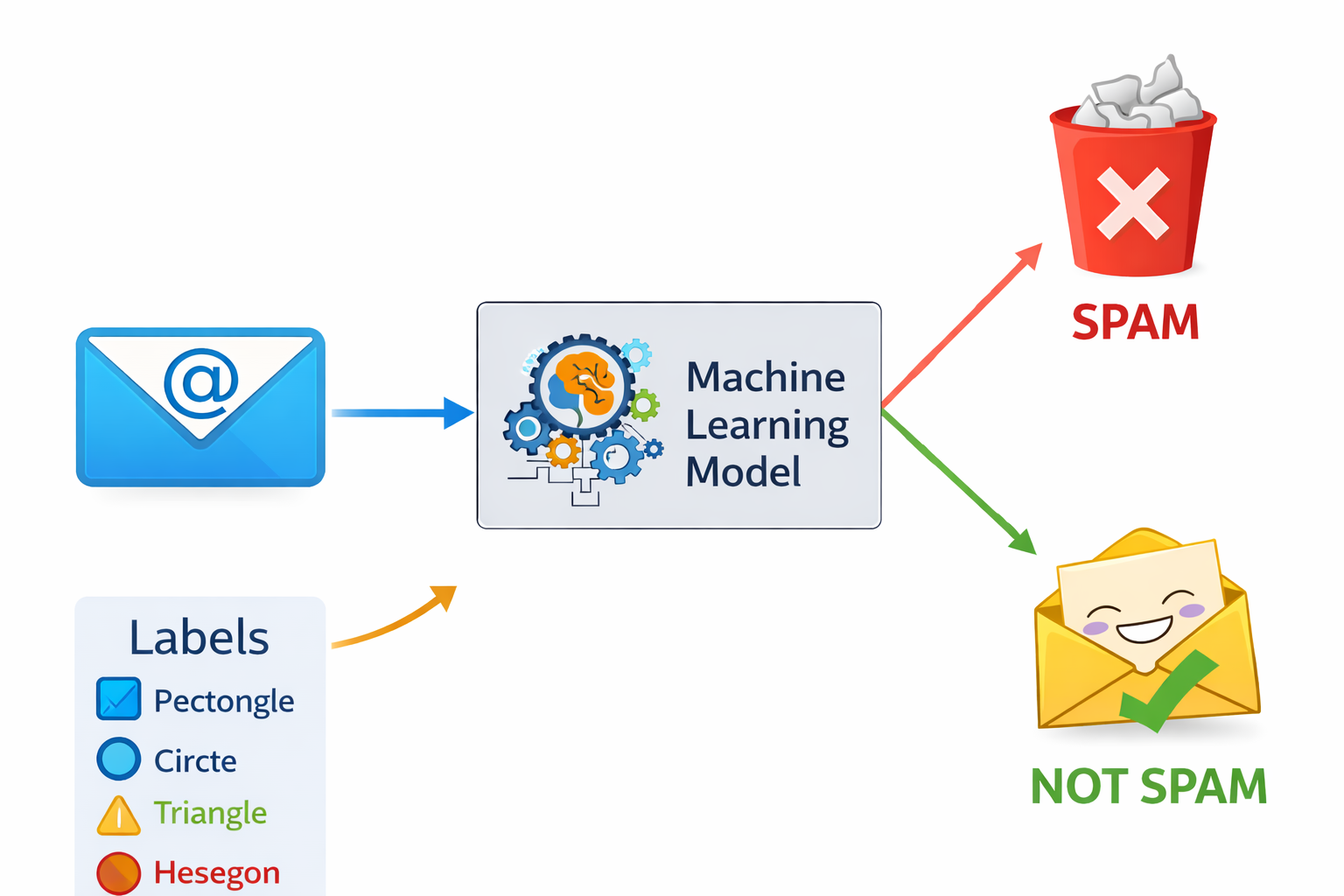
Binary Classification digunakan ketika jumlah kategori hanya dua. Model bertugas menentukan apakah suatu data termasuk ke kelas pertama atau kelas kedua. Contoh: ya atau tidak, spam atau bukan spam, normal atau tidak normal.
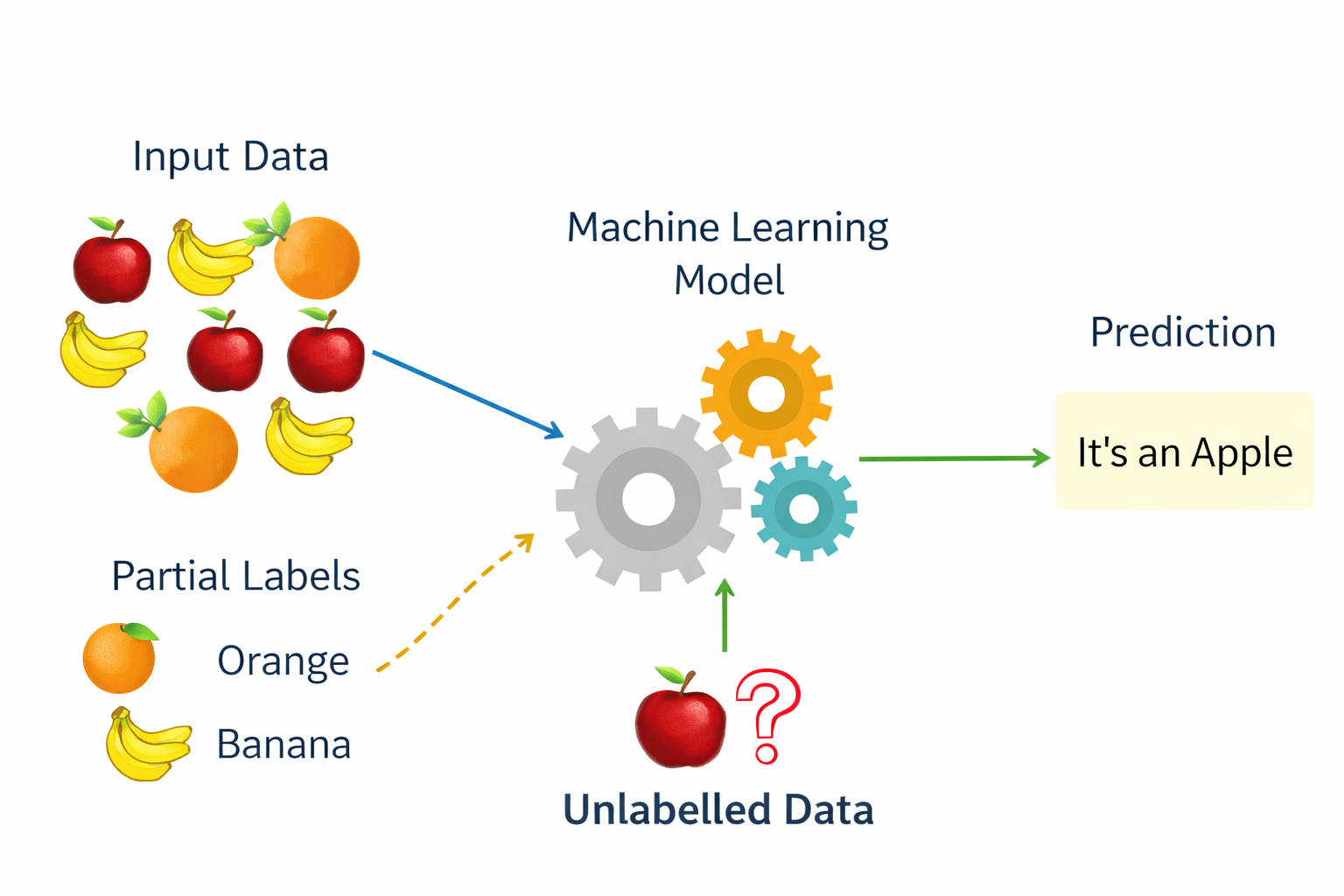
Multi-Class Classification digunakan ketika jumlah kategori lebih dari dua. Model akan memilih satu kelas yang paling sesuai dari beberapa kategori yang tersedia. Contoh: klasifikasi jenis buah (apel, jeruk, pisang), atau pengenalan angka (0–9).
Inti Klasifikasi
Dengan menggunakan model klasifikasi, sistem dapat mengambil keputusan kategorikal berdasarkan pola yang dipelajari dari data sebelumnya. Metode ini banyak digunakan dalam berbagai aplikasi seperti pengenalan wajah, analisis teks, sistem diagnosis, dan deteksi kondisi tertentu.
Contoh Klasifikasi
Email spam detection: to classify email as “spam” or “not spam”.
Fruit image classification: to classify fruit as “Apple”, “Banana”, “Orange”, etc.
Regresi
Regresi adalah salah satu metode dalam supervised learning yang digunakan untuk memprediksi nilai kontinu atau nilai numerik. Berbeda dengan klasifikasi yang menghasilkan kategori atau kelas tertentu, regresi menghasilkan nilai berupa angka yang dapat berada dalam rentang tertentu.
Dalam regresi, model dilatih menggunakan data berlabel, di mana setiap data input memiliki nilai target yang bersifat kontinu. Model kemudian mempelajari hubungan antara variabel input dan output untuk menghasilkan prediksi yang mendekati nilai sebenarnya.
Contoh Regresi
Prediksi Harga Rumah
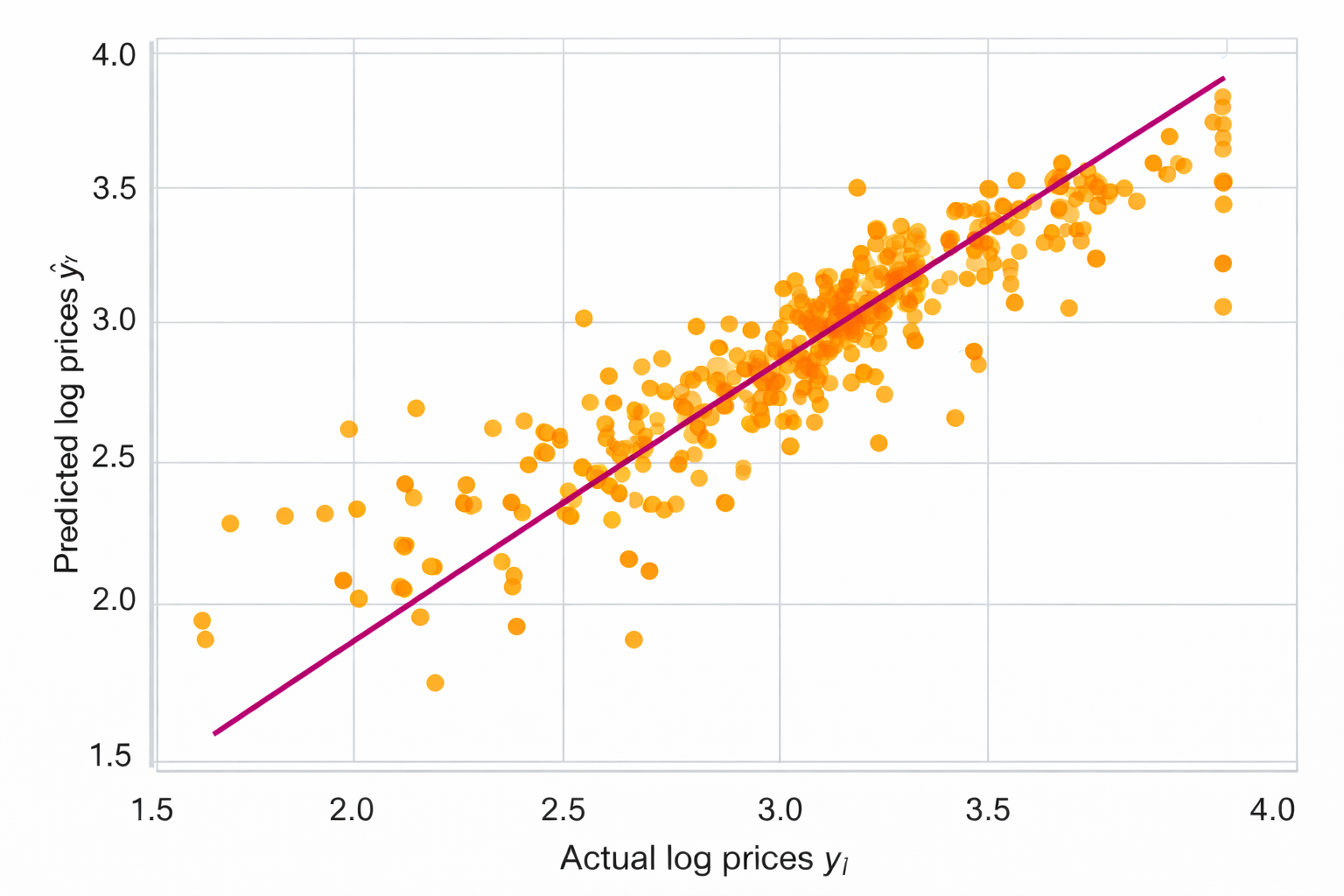
Inti Regresi
Tujuan utama regresi adalah memperkirakan nilai numerik di masa depan berdasarkan pola yang ditemukan dari data sebelumnya. Oleh karena itu, metode regresi sangat penting dalam bidang ekonomi, bisnis, keuangan, dan analisis data.
Algoritma Supervised Learning
1. Linear Regression
Linear Regression adalah algoritma supervised learning yang digunakan untuk memprediksi nilai angka (kontinu) dengan cara mencari hubungan linear antara data input dan output. Contoh: memprediksi harga rumah berdasarkan luas bangunan.
2. Logistic Regression
Logistic Regression adalah algoritma supervised learning yang digunakan untuk klasifikasi, terutama binary classification. Meskipun namanya regresi, algoritma ini menghasilkan kelas atau probabilitas, bukan nilai kontinu. Contoh: menentukan email termasuk spam atau tidak.
3. Naïve Bayes Classifier
Naïve Bayes adalah algoritma klasifikasi yang bekerja berdasarkan teorema probabilitas Bayes dengan asumsi sederhana bahwa setiap fitur saling independen. Algoritma ini cepat dan efektif untuk data teks. Contoh: klasifikasi sentimen positif atau negatif.
4. Decision Tree
Decision Tree adalah algoritma yang membuat struktur pohon keputusan untuk mengklasifikasikan atau memprediksi data. Keputusan diambil berdasarkan serangkaian aturan if–then. Contoh: menentukan kelayakan pinjaman berdasarkan pendapatan dan usia.
5. Support Vector Machine (SVM)
Support Vector Machine adalah algoritma supervised learning yang bekerja dengan mencari garis atau batas terbaik (hyperplane) untuk memisahkan data ke dalam kelas-kelas yang berbeda. SVM efektif untuk data dengan dimensi tinggi. Contoh: pengenalan wajah atau tulisan tangan.
Alur Kerja Supervised Learning
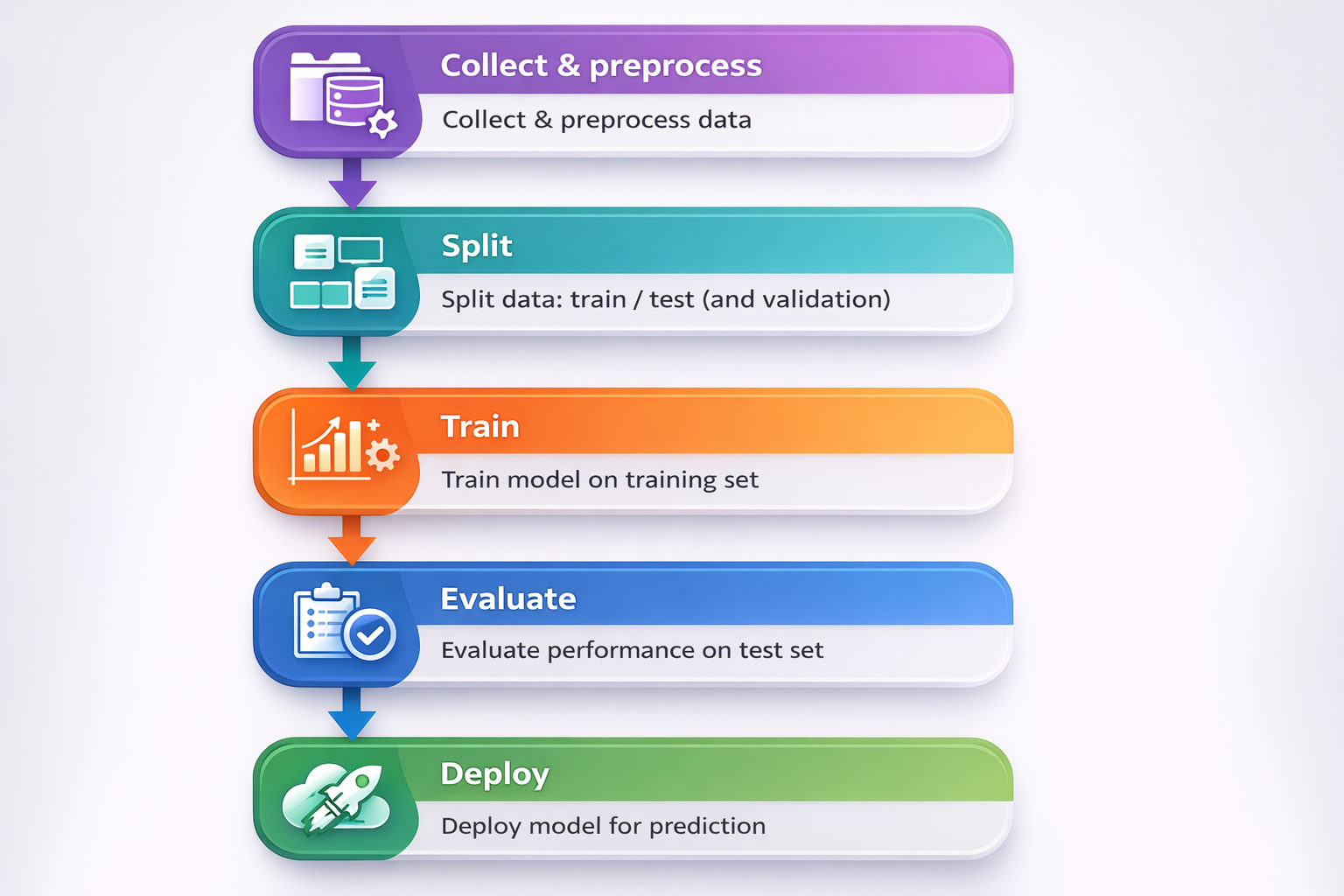
1. Collect & Preprocess Data
a. Collect data adalah tahap awal dalam proses machine learning yang bertujuan untuk mengumpulkan data dari berbagai sumber. Data yang dikumpulkan akan menjadi bahan utama dalam proses analisis dan pemodelan.
Sumber data dapat berasal dari:
- Database (misalnya data transaksi atau data akademik)
- Sensor (seperti sensor suhu, kamera, atau IoT devices)
- API (mengambil data dari layanan atau platform tertentu)
- File (CSV, Excel, JSON, dan lain-lain)
Kualitas dan kelengkapan data pada tahap ini sangat memengaruhi hasil akhir model.
b. Preprocessing data adalah proses menyiapkan dan membersihkan data mentah agar siap digunakan oleh algoritma machine learning. Data mentah sering kali tidak sempurna, sehingga perlu dilakukan berbagai tahapan pengolahan.
Beberapa tugas utama dalam preprocessing meliputi:
- Menangani data yang hilang (missing values): Dilakukan dengan cara mengisi nilai yang hilang (imputation) atau menghapus data yang tidak lengkap.
- Mengubah data kategorikal menjadi numerik: Misalnya menggunakan teknik one-hot encoding, agar data dapat diproses oleh model.
- Normalisasi atau scaling data numerik: Bertujuan menyamakan skala nilai fitur agar model belajar lebih stabil dan cepat.
- Menghapus outlier dan data noise: Untuk mengurangi pengaruh data ekstrem atau tidak wajar yang dapat merusak proses pembelajaran.
c. Libraries for data processing:
- pandas → data manipulation (read_csv, DataFrame)
- numpy → numerical operations
- scikit-learn (sklearn.preprocessing) → scaling, encoding
- missingno → visualize missing data
- nltk / spaCy → text preprocessing (for NLP tasks)
d. Key Libraries for Scraping
- Selenium – browser automation
- Scrapy – scalable spiders, throttling, pipelines
- newspaper4k / newspaper3k – article parsing (title, authors, text)
2. Split Data
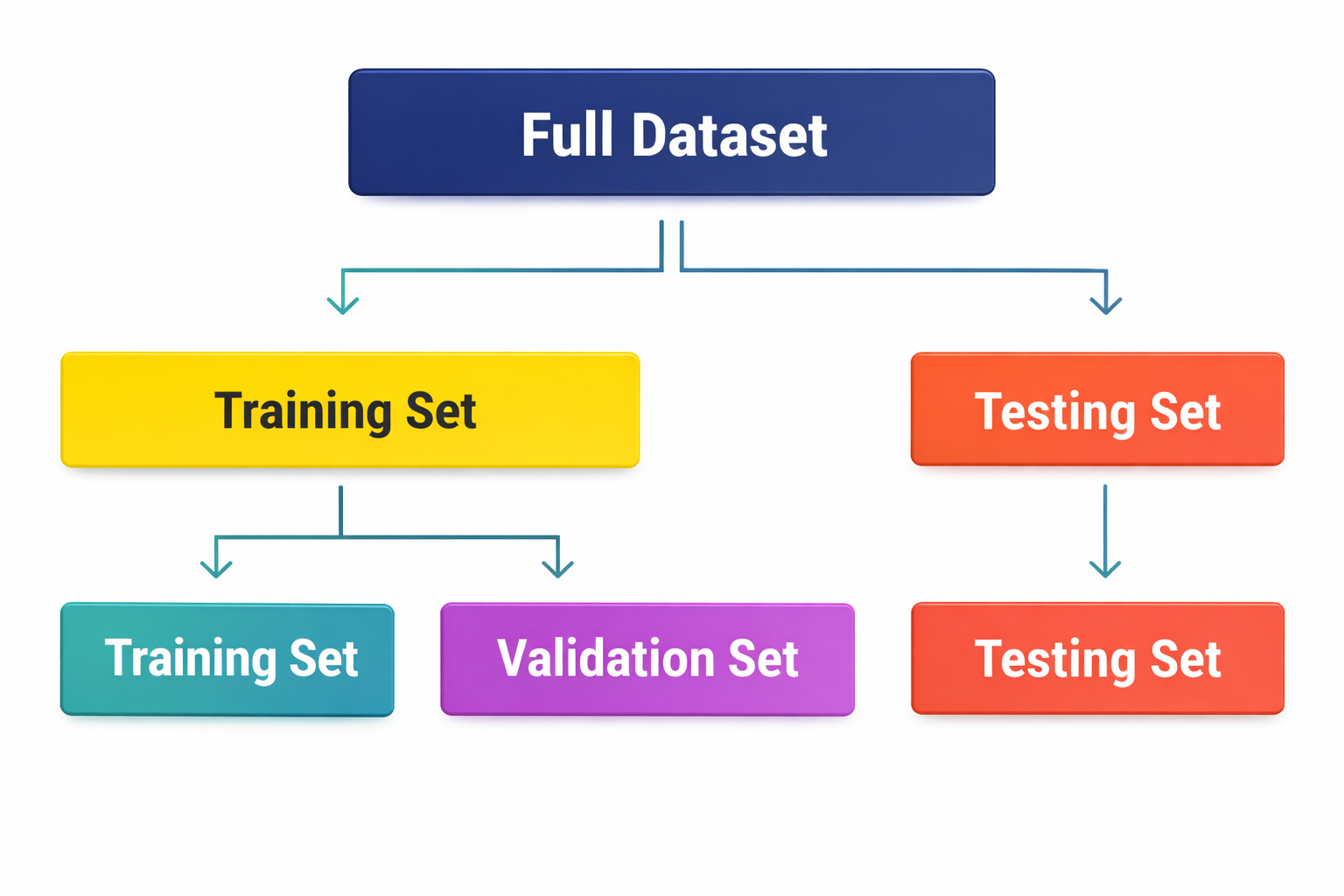
Split data adalah proses membagi dataset menjadi beberapa bagian untuk memastikan model machine learning dapat dilatih dan dievaluasi dengan baik. Pembagian data ini bertujuan agar model tidak hanya bekerja baik pada data latih, tetapi juga mampu menggeneralisasi ke data baru.
- Training set digunakan untuk melatih atau membangun model.
- Validation set (opsional) digunakan untuk menyetel parameter model (hyperparameter).
- Test set digunakan untuk mengukur kinerja model pada data yang belum pernah dilihat sebelumnya.
Umumnya, data dibagi dengan rasio 70% data latih, 15% data validasi, dan 15% data uji. Penting untuk menghindari data leakage, yaitu memastikan data uji tidak tercampur ke dalam proses pelatihan agar hasil evaluasi tetap objektif.
Cross-validation adalah teknik evaluasi model yang digunakan untuk menilai kinerja model secara lebih andal dibandingkan hanya menggunakan satu kali pembagian data latih dan data uji. Metode ini membantu memastikan bahwa model tidak bergantung pada satu pembagian data tertentu.
Cara Kerja
Dataset dibagi menjadi K bagian (fold).
- Model dilatih menggunakan K−1 fold
- Model diuji menggunakan 1 fold
Proses ini diulang sebanyak K kali, sehingga setiap fold pernah menjadi data uji satu kali. Hasil akhirnya adalah rata-rata skor performa, yang dianggap sebagai kinerja model secara keseluruhan.
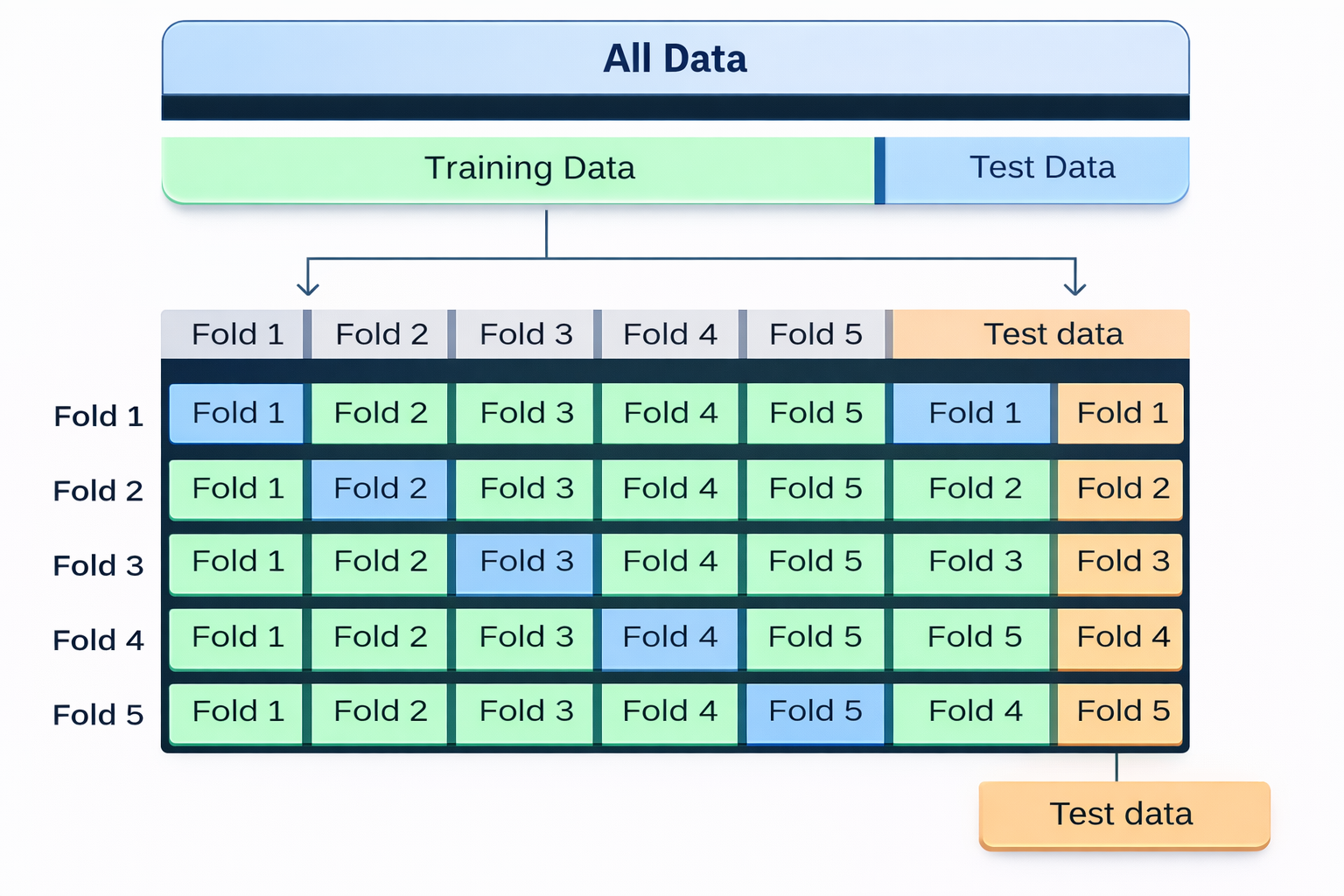
Jenis-Jenis Cross-Validation
- K-Fold Cross-Validation: Metode yang paling umum digunakan, data dibagi menjadi K bagian secara merata.
- Stratified K-Fold: Digunakan untuk data tidak seimbang (imbalanced), karena menjaga proporsi kelas pada setiap fold.
- Leave-One-Out (LOO): Setiap satu data digunakan sebagai data uji, sementara sisanya sebagai data latih. Metode ini sangat teliti tetapi membutuhkan waktu komputasi lebih besar.
3. Train Model pada Training Set
Training model adalah proses melatih algoritma machine learning menggunakan data latih (training set) agar model mampu mempelajari pola dari data dan menghasilkan prediksi yang akurat. Pada tahap ini, data dimasukkan ke dalam model dan parameter internal model disesuaikan secara bertahap.
a. Bagaimana Proses Training Bekerja?
Input:
- Features (X) → data masukan
- Labels (y) → nilai atau kelas yang benar
b. Proses Training:
- Data latih dimasukkan ke dalam model yang dipilih.
- Model menghasilkan prediksi (ŷ).
- Hasil prediksi dibandingkan dengan nilai sebenarnya (y) menggunakan loss function untuk menghitung kesalahan.
- Algoritma optimasi (misalnya Gradient Descent) digunakan untuk memperbarui parameter model seperti bobot (weights), koefisien, atau aturan pemisahan (splits).
- Proses ini diulang berkali-kali hingga model konvergen, yaitu saat kesalahan sudah minimum atau tidak banyak berubah
c. Tujuan Training Model
Tujuan utama dari training model adalah:
- Meminimalkan error (loss) antara prediksi dan nilai sebenarnya
- Menemukan parameter terbaik agar model dapat menggeneralisasi dengan baik saat diuji menggunakan data baru yang belum pernah dilihat sebelumnya
d. Python Libraries for Training:
- scikit-learn → classical ML (LogisticRegression, DecisionTree, SVM, etc.)
- xgboost / lightgbm / catboost → advanced boosting models
- tensorflow / pytorch → deep learning frameworks
- Hugging Face 🤗 Transformers → pretrained models for NLP, vision, audio; BERT, GPT-2/3, RoBERTa, DistilBERT, Vision Transformers (ViT), Whisper (speech); Easy fine-tuning on your dataset
4. Evaluasi Performa Model
Evaluasi model adalah proses menguji kinerja model machine learning menggunakan data uji (test data) atau data validasi untuk mengetahui seberapa baik model bekerja pada data yang belum pernah dilihat sebelumnya. Tahap ini sangat penting untuk memastikan bahwa model tidak hanya bagus saat dilatih, tetapi juga mampu menggeneralisasi dengan baik.
a. Metode Evaluasi Berdasarkan Jenis Masalah
- Evaluasi untuk Klasifikasi
Beberapa metrik yang umum digunakan:
- Accuracy: persentase prediksi yang benar
- Precision: ketepatan model dalam memprediksi kelas positif
- Recall: kemampuan model menemukan semua data kelas positif
- F1-score: keseimbangan antara precision dan recall
- Confusion Matrix: tabel untuk melihat detail prediksi benar dan salah
- Evaluasi untuk Regresi
Metrik yang sering digunakan:
- MSE (Mean Squared Error): rata-rata kuadrat kesalahan
- RMSE (Root Mean Squared Error): akar dari MSE, lebih mudah diinterpretasikan
- R² (R-Squared): seberapa baik model menjelaskan variasi data
b. Overfitting dan Underfitting
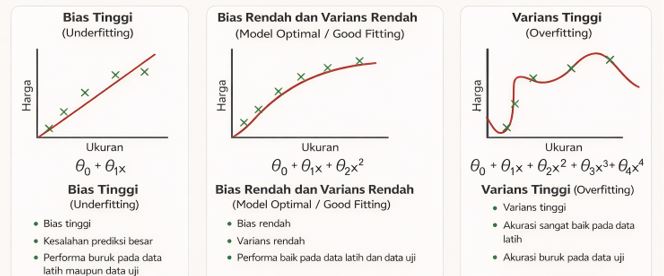
- Overfitting: model terlalu kompleks, sangat baik di data latih tetapi buruk di data uji
- Underfitting: model terlalu sederhana sehingga gagal menangkap pola data
Tujuan evaluasi adalah menemukan keseimbangan yang tepat, yaitu model tidak terlalu sederhana dan tidak terlalu kompleks.
c. Perbaikan Model
Jika performa model masih rendah, beberapa langkah yang bisa dilakukan:
- Memperbaiki atau menambah fitur (feature engineering)
- Mencoba algoritma lain
- Melakukan tuning hyperparameter
d. Library Python untuk Evaluasi Model
- scikit-learn.metrics: Digunakan untuk menghitung metrik evaluasi seperti accuracy_score, precision_score, r2_score, dan confusion_matrix.
- matplotlib / seaborn: Digunakan untuk visualisasi hasil evaluasi, seperti confusion matrix dan kurva error.
5. Deployment
Deploy model adalah tahap menerapkan model machine learning yang telah dilatih agar dapat digunakan untuk melakukan prediksi pada data baru di dunia nyata. Pada tahap ini, model tidak lagi hanya diuji di lingkungan pengembangan, tetapi diintegrasikan ke dalam aplikasi atau sistem yang dapat diakses oleh pengguna.
a. Tugas Utama dalam Model Deployment
- Menggunakan model terlatih untuk memprediksi data baru
- Menyimpan dan memuat model agar bisa digunakan kembali tanpa perlu melatih ulang
- Mengintegrasikan model ke dalam aplikasi web, sistem backend, atau layanan cloud
b. Library dan Platform untuk Deployment
- Pickle / Joblib
Digunakan untuk menyimpan (save) dan memuat (load) model machine learning yang telah dilatih. 👉 Memudahkan penggunaan ulang model tanpa training ulang.
- Flask / FastAPI
Framework Python untuk mendeploy model sebagai web service (API). Aplikasi lain dapat mengirim data ke API dan menerima hasil prediksi dari model. 👉 Cocok untuk sistem berbasis web dan backend.
- Streamlit / Gradio
Digunakan untuk membuat aplikasi interaktif dengan cepat tanpa banyak kode. Pengguna dapat langsung memasukkan data dan melihat hasil prediksi melalui antarmuka visual. 👉 Cocok untuk demo, prototipe, dan edukasi.
c. Hugging Face Hub
Hugging Face Hub adalah platform untuk mengunggah, menyimpan, dan membagikan model serta dataset, terutama untuk model berbasis transformers.
Fitur utama:
- Upload & share model secara publik atau privat
- Inference API untuk menjalankan model langsung di cloud tanpa setup server
- Hugging Face Spaces untuk mendeploy model sekaligus UI menggunakan Gradio atau Streamlit
Tujuan deployment adalah membuat model siap digunakan secara nyata, mudah diakses, dan mampu memberikan prediksi yang konsisten dan andal pada data baru.



